Blog
Methodological pitfalls of traditional Marketing Mix Modeling
May 14, 2021 | Chris Kervinen

As we go into the 2020s, traditional Marketing Mix Modeling (MMM) just won’t cut it anymore.
A recent study by Google (2017) reveals that the older models and techniques seem to fall especially short in three areas: data limitations, selection bias, and model validation.
Statistical models used by marketers to measure the effectiveness of their advertising spend have been around in various forms since the 1960s. The natural selection has favored regression analysis above other lifeforms, and not least because it’s somewhat easily grasped and implemented regardless of the company size or marketing environment. But as time goes by, older versions become obsolete and new, smarter ways of life ascend the food chain (as homo sapiens we ought to know).
The reactions are surprisingly similar for each generation: “Things used to be simple and straight-forward back in the days!”. Which is true. The amount of complexity and stimulus has increased exponentially throughout the decades, which in turn has slowly eroded the feasibility of the simpler and slower analysis tools.
Older solutions might have their nostalgia and simplicity, but they fall short when it comes to effectiveness and applicability to today’s hectic environment . Image from Quotesgram.
It’s always difficult to let go of things, but there are three aspects you should consider when comparing the traditional MMM and the newer tech-driven solutions.
Data limitations
The data range, quality and quantity vary a lot from modeling to modeling, as there are no agreed rules or “golden standards”. One rule of thumb, conjectured by Good and Hardin, is N=m^{n}, where N is the sample size, n is the number of independent variables and m is the number of observations needed to reach the desired precision if the model had only one independent variable.
This crude precept includes a few issues:
· Models utilize “high-level” data. More often than not the modeler has averaged (e.g. average receipt value) or summed (e.g. weekly or even monthly sales data) at her/his disposal. And that’s what you have to work with. So, you develop a model that explains as much as possible with as little data as possible. But these top-down interpretations can be dangerous, especially when making big business decisions. Day-product-media level data is strongly recommended if your aim is to get insights with any trustworthiness and accuracy. Don’t settle for any less.
· Media data is not modified in any way. When the model looks at things “as is”, it can’t take into consideration some of the more discreet effects, such as adstock (the fact that ads can also have impact on the following days). The effect fades with each passing day of course, but it’s still attributable if the model has been trained to do so. Which it in most cases hasn’t. Moreover, it’s possible that the some of the sales uplift is delayed, which might be the case especially with bigger purchases. A good example of literally big purchases could be when you decide that Monday is not the best day to go shopping for that new sofa. You’ll save the “pleasure” for the weekend.
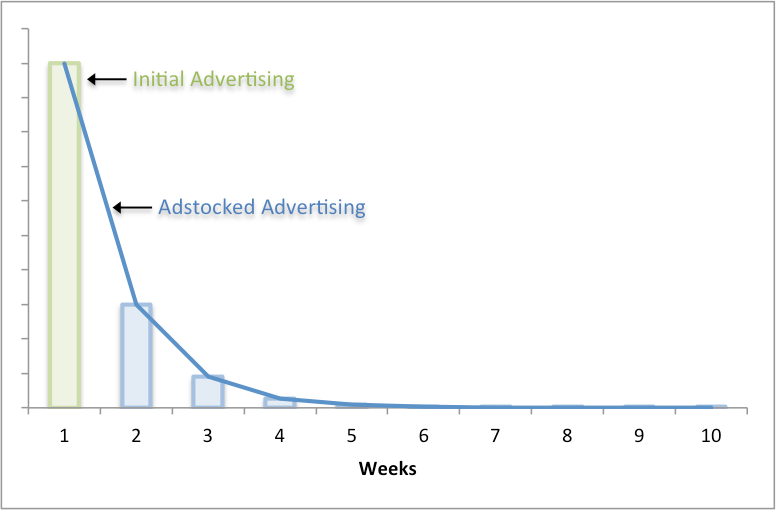
Without any media data modifications, the model misses important information about the ad effectiveness during following days. Image from Gabriel Mohanna’s blog
· Limited variation within the data range. MMM is often applied to provide answers for “what if” -scenarios. But – what if – the modeler wants to estimate the outcomes with substantially different media mix? As traditional MMM can’t calculate media-level declining marginal uplifts, the models tend to assume that the existing trends will continue to certain extent (based on the model). And it can be difficult to justify bigger marketing budget with assumptions, rather than hard numbers.
Selection bias
Not being able to recognize crucial demand variables that correlate with the input media variable represents probably the biggest pitfall in traditional MMM. When these type of demand variables are neglected, the model yields inaccurate, often wildly overvalued media ROIs.

Below the selection bias effect is described through three short horror stories (reader discretion is advised)
· Death comes in March (Seasonality)
Every Spring Jon purchases the front page on the national newspaper for his campaign launch. This has been a tradition for years, and it has always ensured a good marketing ROI for the campaign. It seems that the whole campaign wouldn’t be there without this media channel.
Due to his exquisite track record Jon decides to pitch the idea of rolling the campaign during Fall, as the sales numbers are looking promising. The CFO seems doubtful, but Jon manages to persuade her with hard data on previous campaigns. Jon gets a green light for the new campaign.
Jon is in a shock when the numbers come in. The campaign flopped, and he has been fired for making such a drastic mistake. But he did everything right! He hired the same agency for creatives, knew from the past the audiences and applied the same media mix with the big (even bigger than in the previous campaigns, actually) front page ad in the newspaper. How could this happen?
The new campaign manager manages to get back on track by including seasonality in the modeling as an explanatory factor. By applying time series analysis, she discovers how the base sales increases during the Fall, and decides to pull back the front page ad. There’s no major impact on sales – instead, the team reaches an all-time high on Spring sales through data-driven budget allocation.
The national newspaper didn’t have any part in the previous campaigns’ success. It was the people’s insatiable need to buy ice cream during the first days of Spring all along…
· The unexpected suspect (Funnel effect)
Mary’s career is skyrocketing. She has taken the company’s marketing performance to a whole new level by investing in Search Engine Marketing aggressively with the leading premise that it’s good to be there when the need arises. The assumption has paid off, and the company’s racking off great sales budgets month after month.
Unfortunate events unfold, and a global pandemic breaks out. Regardless of the previous results, the marketing budget is being slashed as a safety measure. Panic spreads like a wildfire, to everyone except Mary. She has a secret ace on her sleeve.
By reallocating the reduced budget from the silly & inefficient Butler-TV ads to SEM, Mary knows she can lever the situation for her benefit. She presents the culprit to the CMO, who accepts the changes and the old Alfred gets to go. There’s no room for butlers in modern organization.
As Mary arrives home her husband meets for at the door. “How did it go” he asks. “Did you discover the bad eggs in your basket?”.
“No”, she replies. “It turned out that the Butler-TV ads were actually driving portion of SEM sales and profit, and we’ve now invested purely on downstream ads. We totally forgot the beginning of the decision journey!”.
“How can this be!” Mary exclaims. “It’s always the butler…”
· Killer deal (Promotion uplift)
After the past stormy six months, Jon and Mary have founded their own agency and made some name for their company. Previous cases have shown that a successful campaign and media management requires careful consideration of what factors are at play in each situation. This time seasonality and funnel effects won’t get the best of this power couple.
A new assignment from a renowned discounter comes in, and Jon and Mary get to work. Jon studies sales and marketing data from the past three years and measures the base sales for the period. Mary reviews how TV spots cause spikes in search engine queries. Both do a thorough job in estimating each media channel’s impact on sales in the upcoming campaign. The couple presents their estimate of the Marketing ROI for the client.
Believe it or not, but the campaign didn’t reach its sales objectives. This time Jon and Mary won’t let it go and decide to implement a market survey. The results reveal that the customers did in fact see the ads and had a need for this type of products.
As none of it makes sense, Mary grabs on to one of the respondent and asks why they preferred the competitor’s offering.
“Your campaign got my attention, for sure” the respondent replied. “But there just weren’t any good promotions that would have made it worth my time to visit the store”.
It was at that moment Jon and Mary realized the competitor had made an offer the customer couldn’t refuse…
As these (fictional?) stories demonstrate, selection bias can be a real nightmare for marketers. But there’s one more monster in the closet when it comes to traditional MMM: Model selection.
Model selection
Ultimately it all comes down to picking the right tool for the job. What is it you want to know in the first place when you’re starting a modeling project? The answer to this question defines the guidelines for model selection in terms of the results and explanatory power – what kind of insights you should be getting, and with what level of certainty.
This might sound like a trivial and obvious thing, but it gets more complex when we focus on what’s true business case behind the modeling. We’re not trying to predict the total sales. Finding out how much money marketing brings in overall isn’t helping us to understand the drivers behind these results. In most cases we want to know how much sales each media drives to determine what’s the most profitable way to allocate the budget between different media channels.
In this context traditional MMM has a lot of shortcomings, as the analysis needs to tap into subtle differences in the data and separate media uplift (sales generated through media visibility) from base sales (sales that would have been reached without any advertising or discounts) and promotion uplift (how much more was sold due to having a discount). Recapping abovementioned pitfalls, we see that the shear complexity of today’s marketing environment, inadequate data sources and focus on individual media channels (in a wide media mix) lead to extremely challenging equation that should be solved.
How to “delay” next-gen MMM
There are a couple tricks you can do to prolong older models’ applicability before the AI-powered supermodels (they’re actually as good as they sound like) take over the industry. Holding on requires two things: 1) Better data and 2) Model evaluation through simulations.

No model likes bad data quality. Whether you’re sticking with the traditional MMM or adopting more advanced tools, investing in data quality is always worth it. Cartoon by Jon Carter .
Better data comes in two flavors. More accurate data and more granular data. It’s a common fact that the collection process for the data that’s used in MMM is itself one of the biggest hurdles. Usually it has been for the advertiser to source their ads exposure data through the agencies which manage their ad campaigns. This often leads to data inconsistencies and inaccuracies, especially in the long run when models and agencies change. In a perfect world the two parties could form an open collaboration, but only time will tell if this is practically applicable solution in the future.
Simulations in turn provide an intriguing tool for the modelers to test out how well different models can analyze, understand and explain certain situations. For example, a series of simulated datasets with increasing lagged media effects, or increasingly correlated media variables could be produced, and the modeler could fit MMMs to these datasets to understand which of the models are able to explain and predict the results the most accurately.
None of these tricks can, however, deny the fact that there are already far more powerful models at the markets. The cycle of life continues, and the Bayesian modeling framework is gaining a bigger and bigger foothold on the industry.
Here’s why (follow-up article coming soon)
Curious to learn more? Book a demo.
Related articles
Read more postsNo items found!